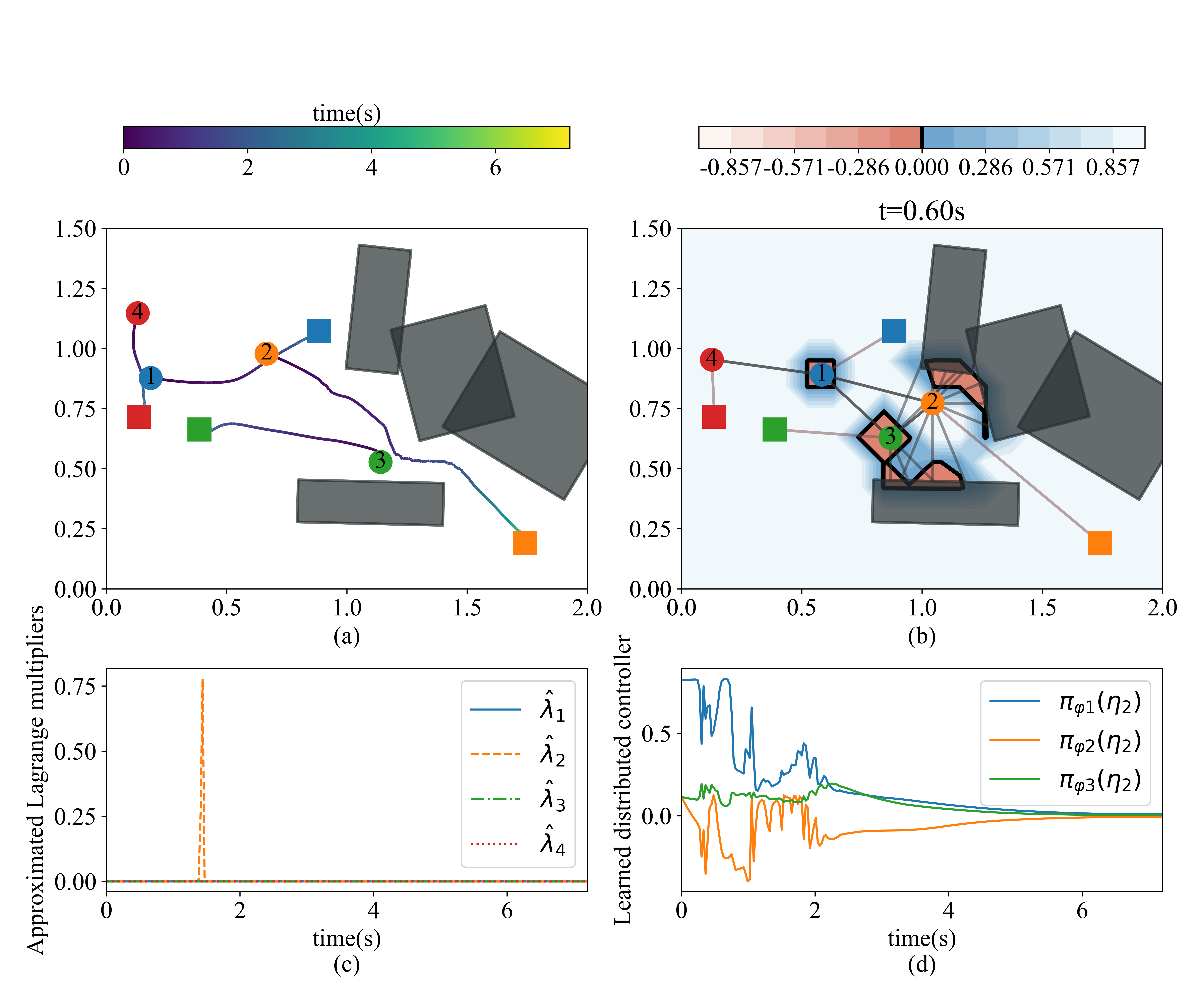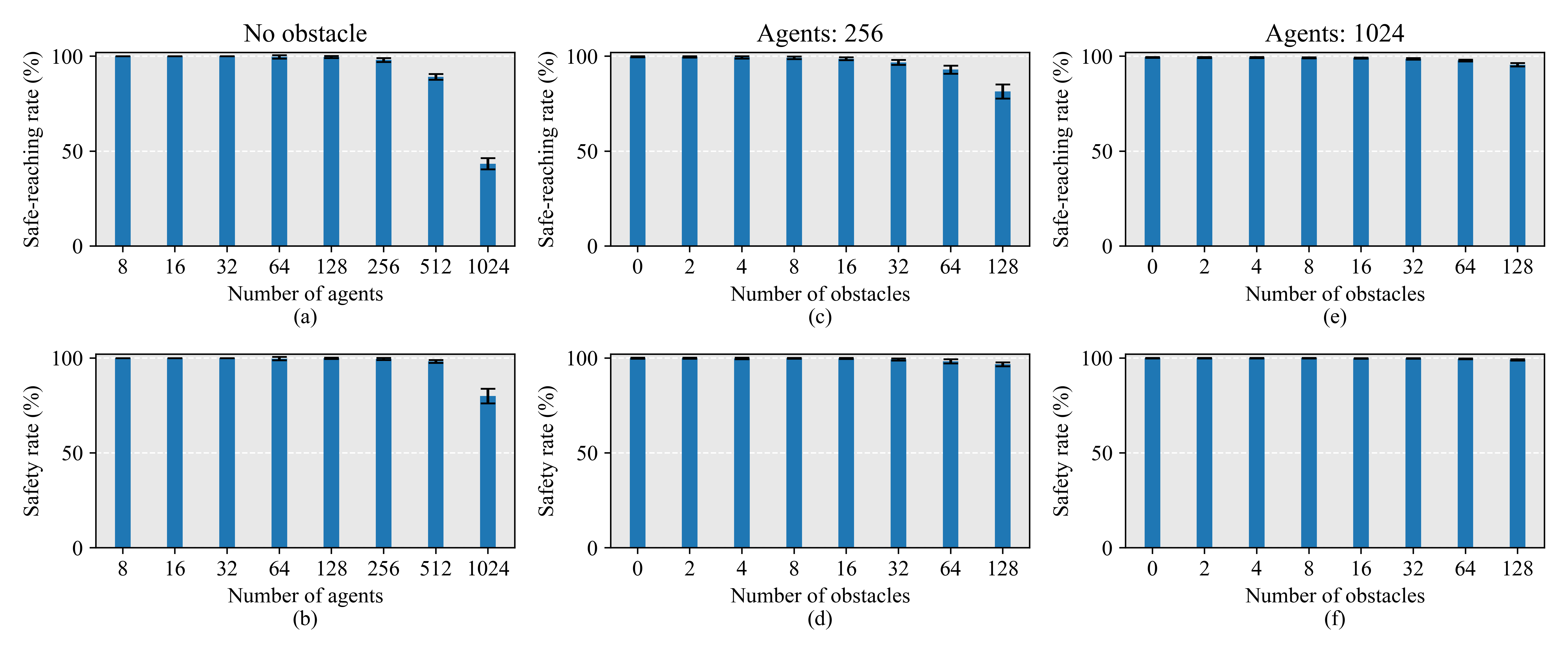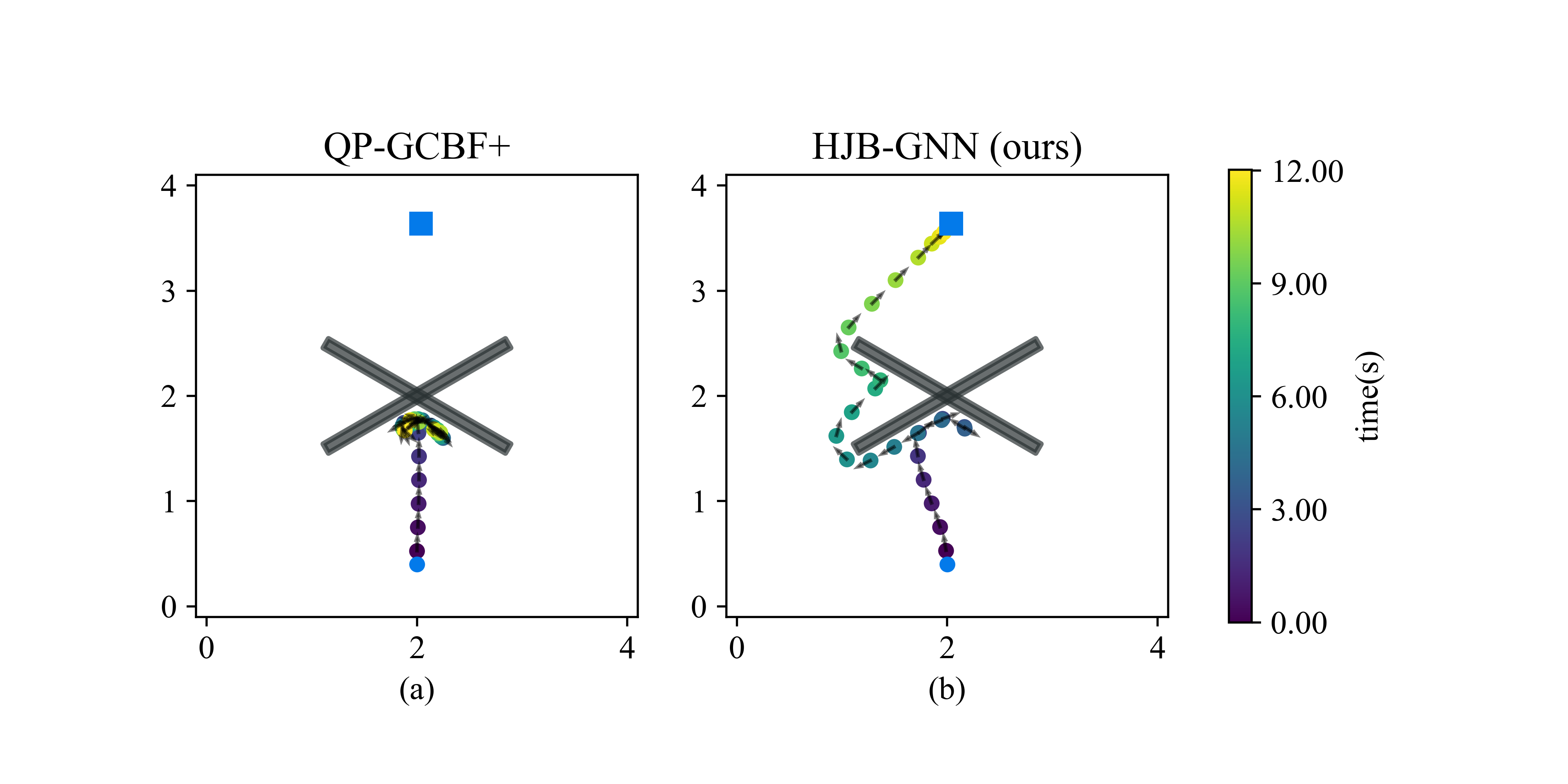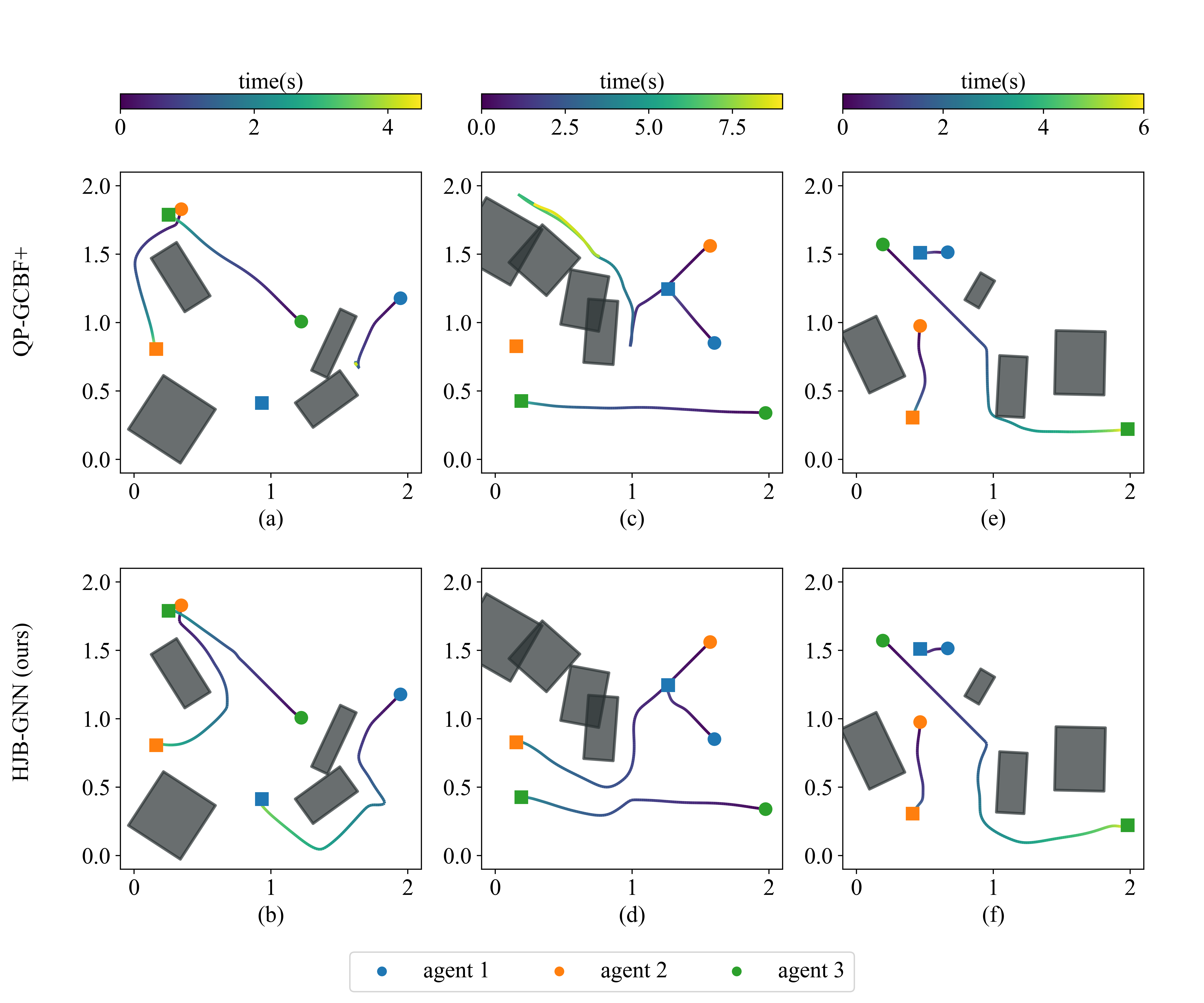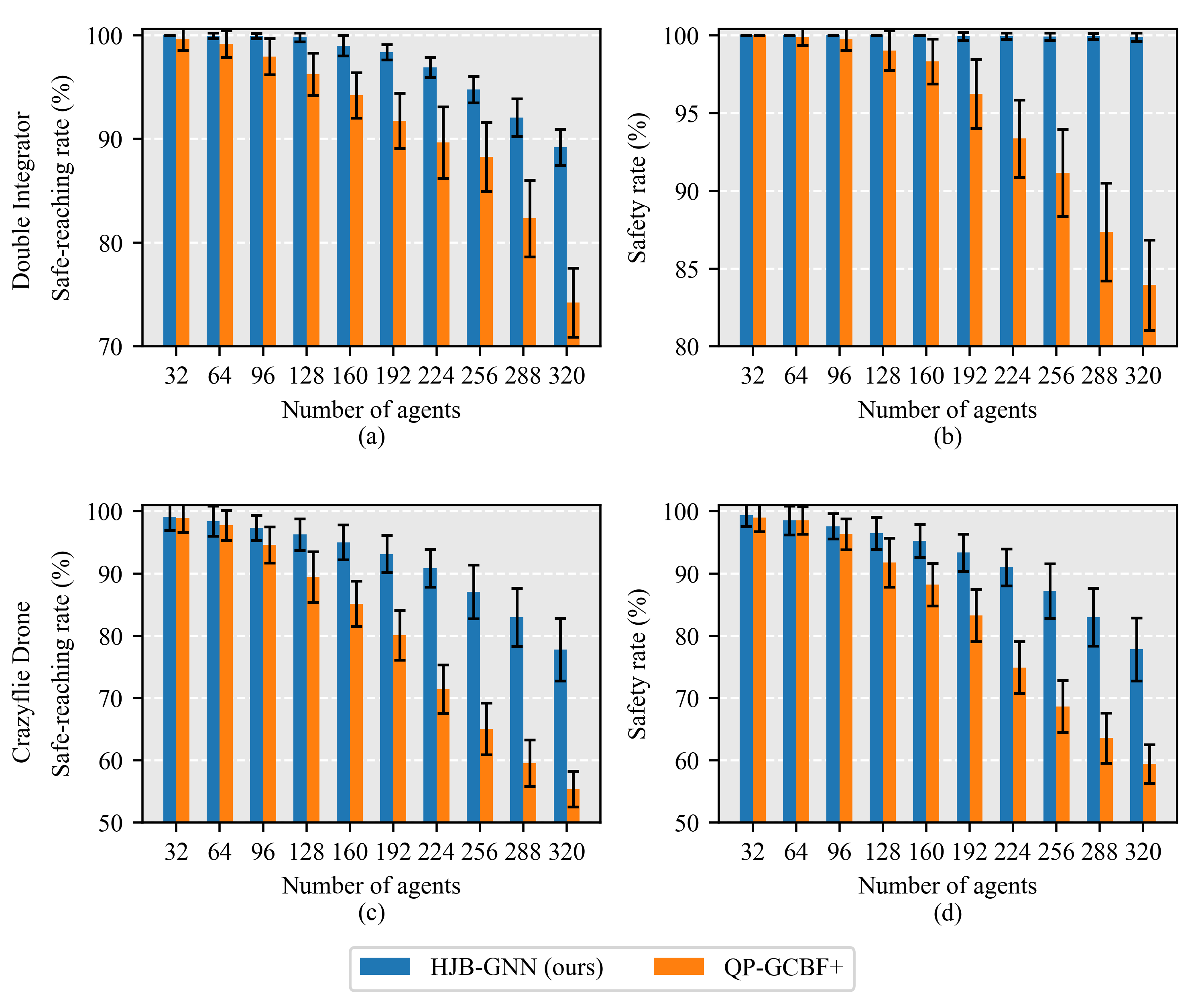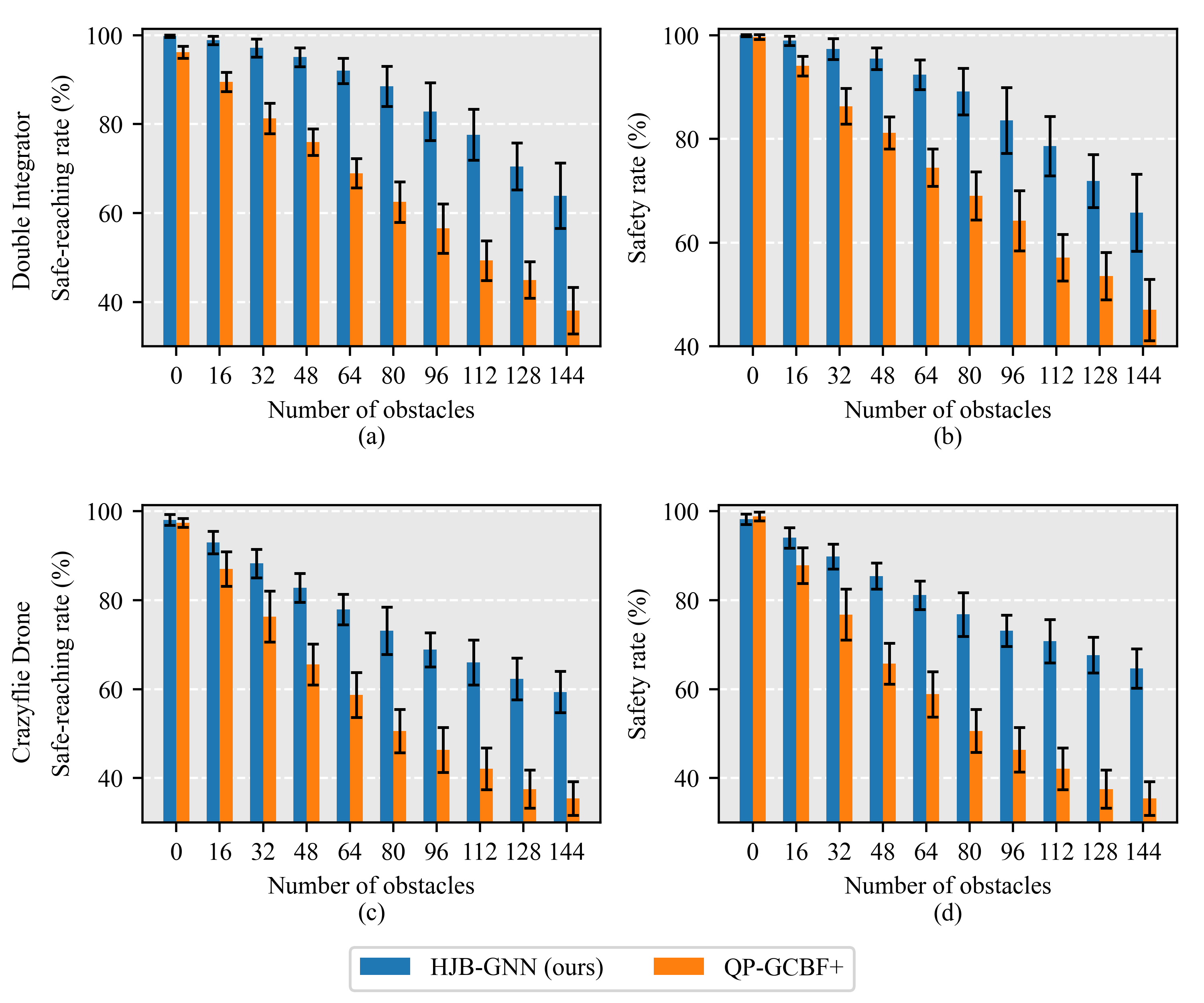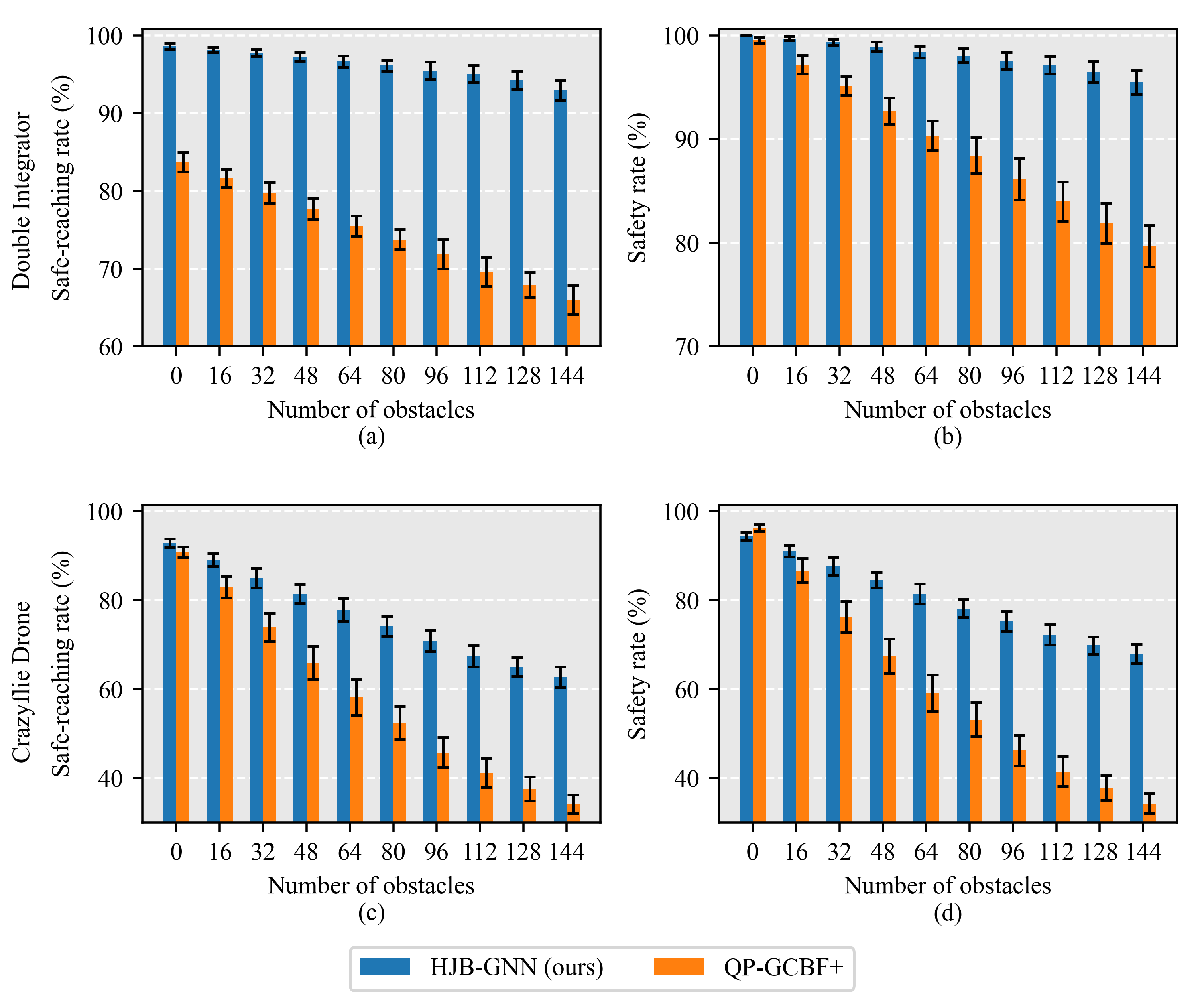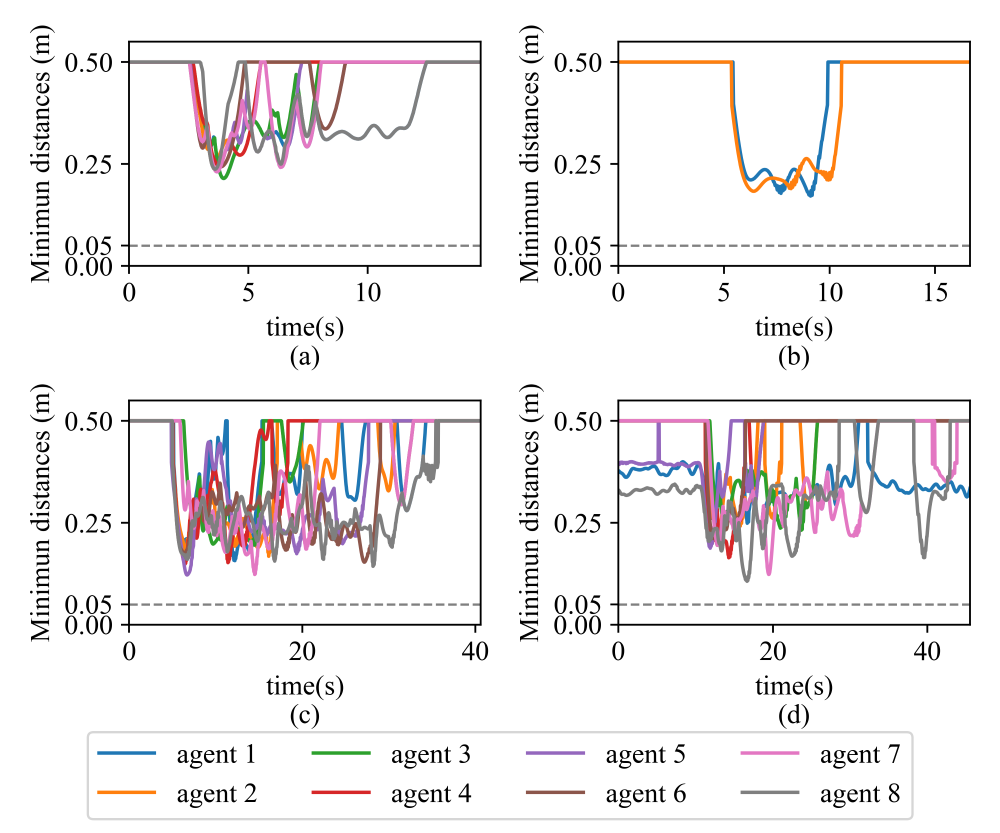
2D environment
3D environment
agents=128, obstacles=0
agents=512, obstacles=0
agents=1024, obstacles=0
agents=16, obstacles=16
agents=32, obstacles=16
agents=32, obstacles=32
agents=64, obstacles=0
agents=128, obstacles=0
agents=512, obstacles=0
agents=32, obstacles=16
agents=64, obstacles=32
agents=128, obstacles=64